Werden Sie noch für das Lesen bezahlt? KI-Agenten revolutionieren die Dokumentenextraktion 
KI ist im Begriff den juristischen Markt zu verändern. Rein wissensbasierte Bots zeigen bisher nur in Einzelsituationen ihren Wert. Aber als Review- und Extraktions-Software wirken Sprachmodelle bereits Wunder, zu einem Bruchteil der Kosten. Kommt jetzt die Dokumenten-Diligence für alle?
Wissensbasierte Bots sind relevant – aber Use Cases noch rar
Der Einfluss der Sprachmodelle auf unsere vornehmlich textbasiert arbeitende Profession scheint erheblich. Doch die „1. Generation“ von Anwendungsfällen sind bisher oft wissensbasierte Bots („Chatbots“), die noch wenig praktischen oder wirtschaftlichen Mehrwert liefern. Der lediglich vereinfachte Zugang zum Rechtswissen wird als wenig wertstiftend angesehen. Und ohne bestätigende Expertenbrand – kurzum: Vertrauen – verbleiben Zweifel bei der Anwendung, vor allem für die Rechtssuchenden. Erfolgreiche Produkte finden sich daher vor allem in der juristischen Recherche für Profis.
Ähnlich ist die Situation im Kundenservice, wo der verbesserte Zugriff auf Wissen zu einem verbesserten Service führt. So arbeitet bei Bertelsmann Arvato das interne Service-Team für HR seit neuestem Bot-basiert: Die über 100 HR-Experten beantworten Mitarbeiterfragen persönlich per E-Mail, Telefon, oder Chat. Sie werden aber von KI-Agenten unterstützt, die auf internes Wissen (Betriebs- und Konzernvereinbarungen) nebst relevanten Rechtsnormen zugreifen. Das spart Zeit, schafft Transparenz und Konsistenz.
Sprachmodelle brauchen „Einbettung“
Weitere lohnende Use Cases sind allerdings rar: Ohne weitere Features bleiben Sprachmodelle bessere Suchfunktionen. Ihr Wert zeigt sich erst bei Verbindung mit weiteren Funktionen, Automationen oder der Einbettung in die weitere Systemlandschaft. Ein gutes Beispiel hierfür ist die Dokumentendurchsicht.
Die „Special Agents“ kommen: ein neuer Ansatz bei der Extraktion
Dokumentenanalyse mit Hilfe von KI war (neben der Dokumentenautomation) seit jeher eines der attraktivsten und relevantesten Marktsegmente. Die KI-unterstützte Dokumentendurchsicht ist in vielen Transaktionen mittlerweile nicht nur Standard, sondern unverzichtbar.
Use Case: Dokumentendurchsicht im Arbeitsrecht
Für Kanzleien und Rechtsabteilungen gehört die Durchsicht großer Dokumentenmengen zum Alltag. Ob Arbeits- oder Immobilienvertrag, Hypothek, Klage oder Versicherungspolice: die Durchsicht erfordert Zeit.
| „Ein Beispiel ist mir aus eigener Erfahrung in Erinnerung geblieben und häufiger Use Case: Die Kontrolle von IP-Transfer-Klauseln in Arbeitsverträgen darauf, ob die Rechte an den Arbeitsergebnissen rechtssicher und vollständig auf das Unternehmen übergehen.“ |
Oft erfolgte die Durchsicht „per Hand“. Zeit- oder Kostendruck lassen oft nur Stichproben einzelner Verträge zu. Die manuelle Durchsicht ist naturgemäß aufwändig und fehleranfällig.
Bislang kam Review-/Extraktions-Software häufig nur bei größeren Transaktionen zum Einsatz, da die Aufwände für das Aufsetzen und Trainieren einem wirtschaftlichen Einsatz entgegenstanden.
Extraktion mit dem KI-Agent: Schnell, einfach, gut genug?
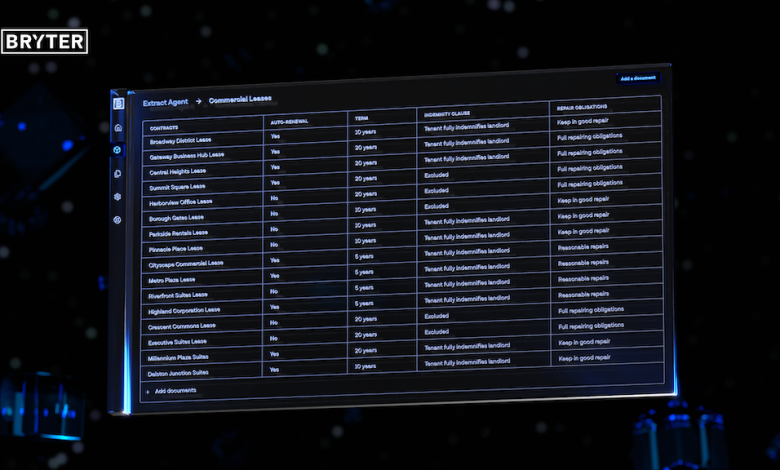
Neue Sprachmodelle stellen insofern einen Quantensprung dar, da nicht mehr für einzelne Dokumententypen oder -klauseln aufwändig trainiert werden muss. Die Extraktion mit dem Sprachmodell ist dagegen überraschend einfach: Unterschiedlichste Dokumentenkonvolute können ohne große Aufwände analysiert und Datenpunkte extrahiert werden.
Die so gewonnenen strukturierten Daten können dann tabellarisch angezeigt, exportiert oder für die Weiterverarbeitung formatiert werden. Benutzer interagieren mit dem System über eine einfache UI. Sprachmodelle bzw. die angewandten KI-Techniken arbeiten dabei unsichtbar im Hintergrund.
| „Im arbeitsrechtlichen Beispiel findet die Software IP-Transfer-Klauseln, kann den Klausel-Text ausgeben oder weitere damit zusammenhängende Fragen beantworten – zum Beispiel ob die Klausel einem bestimmten Format entspricht. Für die Verträge ohne entsprechende Klausel können die Anschreiben nebst Zusatzvereinbarung zum Vertrag gleich generiert werden.“ |
Sprachmodelle + Validierung + Workflow
Der Aufbau des Extraktions-Agenten verbindet drei Komponenten:
1. Eine Retrieval-Augmented-Generation (kurz: RAG) unter Zuhilfenahme eines Sprachmodells liest den Inhalt ein, findet relevante Passagen, und generiert Antworten.
2. Eine Extraktions-KI formalisiert und validiert die Daten und macht sie verarbeitungsfähig.
3. Danach werden weitere Funktionen wie Automationen, Dokumentengenerierung oder Prozesse angeschlossen. Dies kann über individuelle Tools oder über eine Workflow-Plattform geschehen.
Im Beispielsfall der Arbeitsverträge ist dieser Prozess sehr einfach: Die KI analysiert die Verträge danach, ob eine IP-Transfer-Klausel enthalten ist. Die Extraktions-KI validiert die Ergebnisse und stellt sicher, dass der Output sauber ist. Im dritten Schritt erstellt eine Automation eine Zusatzvereinbarung zum Vertrag. Das Ergebnis: Vertragsdurchsicht und Repapering in einem Durchlauf.
Gegenüber herkömmlichen Analyse-Ansätzen haben diese GenAI-Agenten bestechende Vorteile:
1. Kein Investment, niedrige Kosten
Herkömmliche KI-Review und -Extraktionstools erforderten das vorherige Trainieren einzelner Datenpunkte für jeden Datenpunkt in der jeweiligen Sprache. Dazu kamen Kosten für die Wartung, Review-Spezialisten und komplexe Datenhygiene und -validierungsprozesse. Diese Kosten entfallen heute zu großen Teilen. Zunehmend verbesserte Sprachmodelle, innovative RAG-Konfigurationen und sinkende LLM-Kosten können die Anwendungskosten weiter senken.
2. Einsparungen für kleine und einmalige Projekte
Damit sind die Einstiegshürden viel geringer. Datenextraktionstools können nunmehr auch bei kleineren Projekten problemlos eingesetzt werden und versprechen hier Effizienzsteigerungen und skalierbare Ansätze.
3. Hohe Flexibilität und Individualisierbarkeit
Die Extraktions-Agenten arbeiten nicht über vortrainierte Datenfelder, sondern im Kern „prompt-basiert“. Dadurch sind diese Systeme wesentlich flexibler und lassen sich – auch während laufender Projekte – problemlos anpassen und konfigurieren.
4. Datenschutz- und Berufsrechtskonformität
Die neuen Sprachmodelle können mit der richtigen „Einbettung“ auch datenschutz- und berufsrechtskonform eingesetzt werden. Dabei können diese, sofern Bedarf besteht, auch lokal (in Deutschland) gehostet werden.
Dokumenten-Analyse-Power für alle?
Kurzum: Moderne Sprachmodelle revolutionieren und demokratisieren Dokumenten-Extraktion und bieten Kanzleien und Rechtsabteilungen, die bislang aufgrund der entstehenden Kosten und Aufwände auf derartige Systeme verzichten mussten, kostengünstige, schnell einsatzbare, sichere und skalierbare Lösungen an die das Potenzial haben, den juristischen Markt nachhaltig zu verändern.
-> Für weitere Informationen besuchen Sie bryter.com
Autor: Michael Grupp ist CEO und Gründer von BRYTER, einem führenden Anbieter von juristischer Automationssoftware. Das Unternehmen hilft Kanzleien, Rechtsabteilungen und Compliance Teams bei der Digitalisierung von Prozessen. BRYTER unterhält Standorte in Frankfurt, London und New York. Zu den Neuentwicklungen von BRYTER gehört auch ein Extraktions-Agent, mit dem sich auch große Dokumentensammlungen analysieren und automatisieren lassen. Michael war als Rechtsanwalt bei HoganLovells und Freshfields im Bereich Litigation tätig bevor er in die Startup-Welt wechselte. Er ist Lehrbeauftragter für Legal Tech und Innovationen an der J.W.Goethe-Universität Frankfurt.